
Over the past few weeks I have been making a webcralwer. I wanted to do it as way to get better at Go with useful for learnings for Graph databases as well as being fun. The project made use of cloud native items such as AWS SQS, DynamoDB and optionally Neptune which could be swapped out for Neo4j.
What is a webcrawler?
A webcrawler or webspider is a program which visits a website, and fetches all of the links on that site and then visits them. This is how sites like Google/Bing/DuckDuckGo get the pages to populate when searching.
Architecture
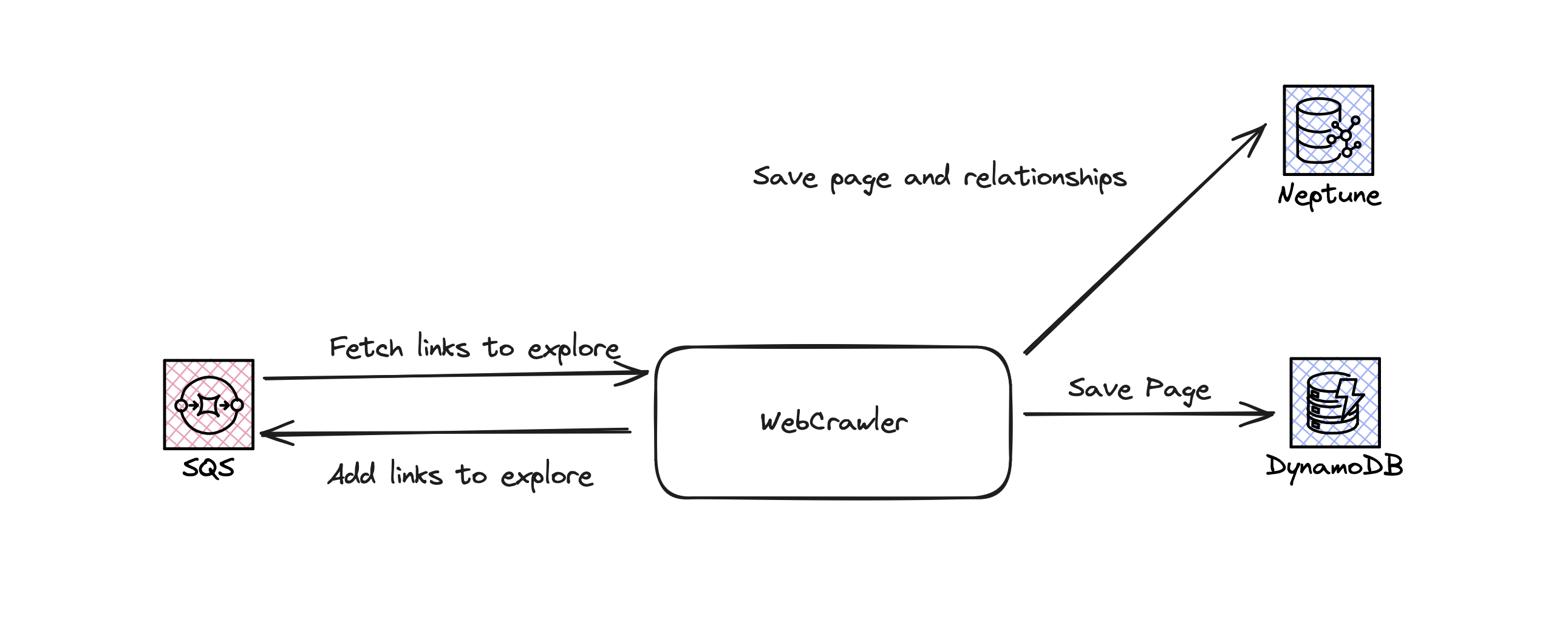
SQS queue
The primary role of the SQS queue was to allow as a store of links to explore. It also if there is an issue processing the link we have a dead letter queue automatically which allows for a high level observability.
It also allows for the program to better scale horizontally. By Allowing multiple nodes to pick up the work.
DynamoDB
This acted as the long term storage of the data. Initially I tried modelling the links between sites inside DynamoDB however this did not work well with the access patterns due to 1MB limit on items in DynamoDB. DynamoDB works excellently as a NoSQL serverless solution for Key value look ups
Neptune/Neo4j
I also used a graph database to store the relationships between pages. This proved much easier than expected. Due to openCypher being a really beginner friendly tool very similar to SQL but allowing for very complex relationships to be models easily. I will be using graph databases in the future for other projects as well.
Take aways
For me it was a fun project which I learnt a lot about some of the major difficulties which Search engines encounter. Such as pages not being formatted correctly, or pages linking to subpages endlessly. In the future I want to build a searching mechanism on top of this to act as a crude full search engine.
For anyone curious here is link to the Github