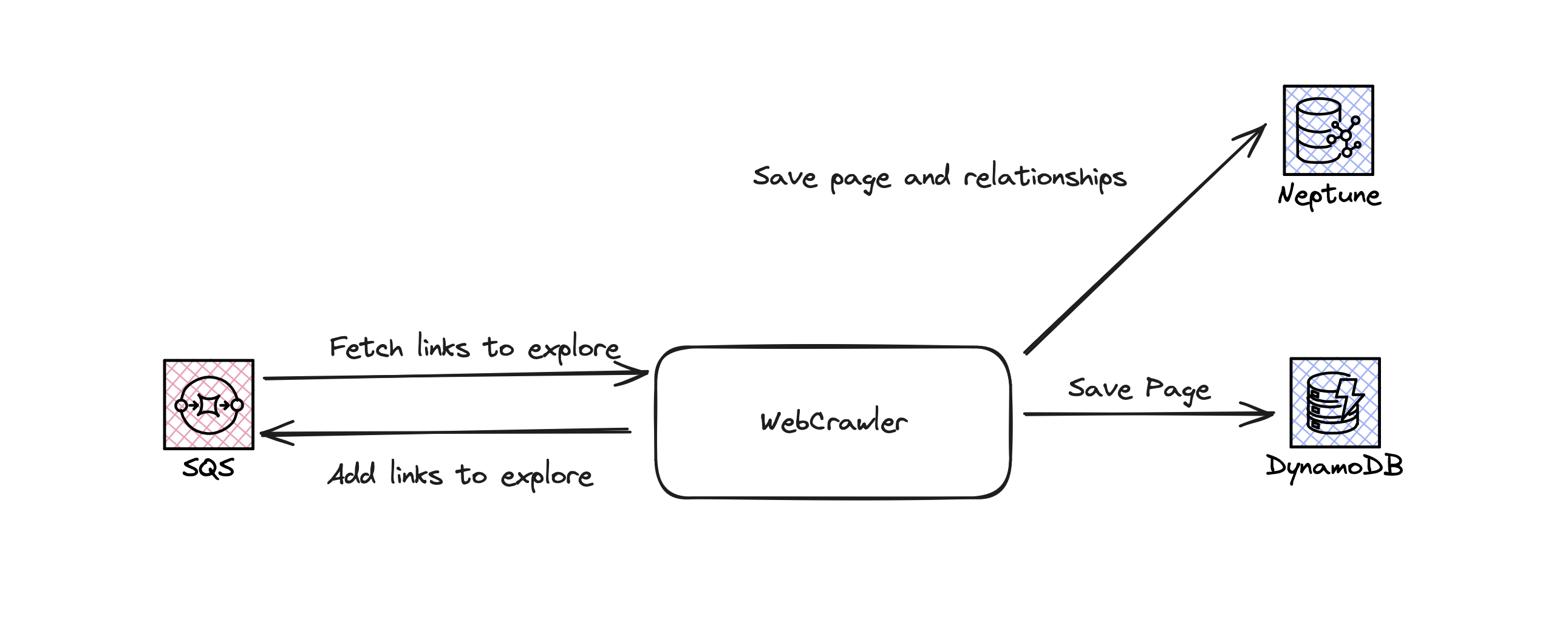
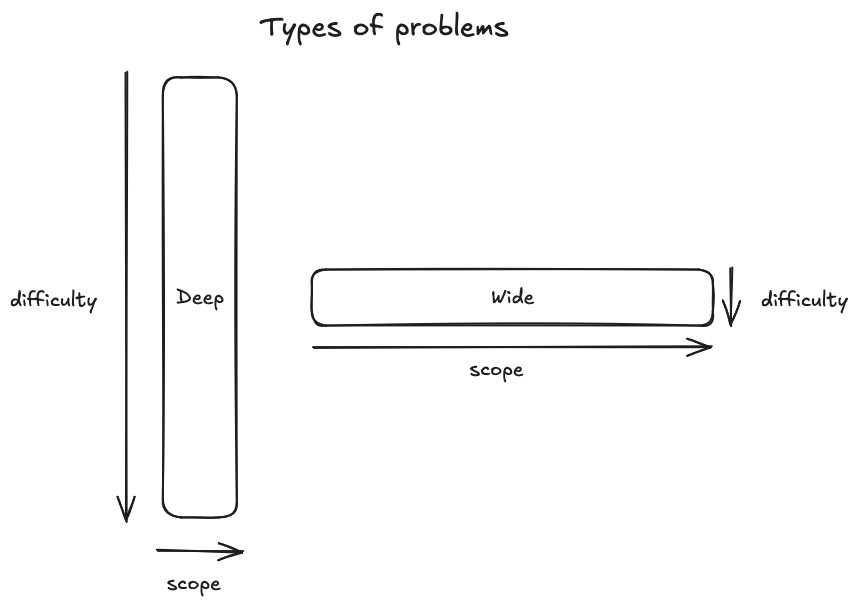
I recently had to explain why a task was taking longer than expected, and I needed a place to vocalise my thoughts, so here we go. In my experience generally there are two kinds of problems which tasks can be put into(not some tasks can be both). Wide problem being something is not necessarily difficult to implement but it’s changes require changes all over the code bases, an example being a blocking mechanism. Deep problems are problems which will be complex but in a very limited domain. An example might be adding a new feature which is distinct and does not rely on too much other code.
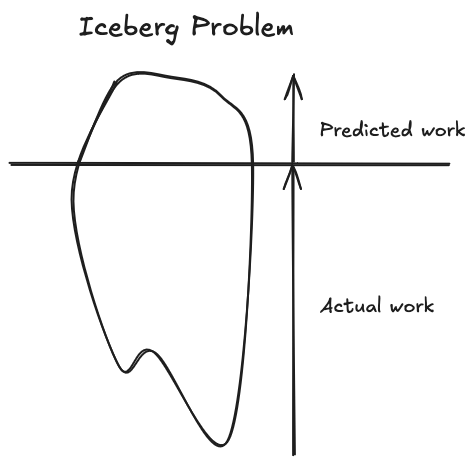
Often wide problems can become what I like to call icebergs where tasks seem simple however their edge case causes the task to drag on. In addition they can upset other existing functionality.
A big problem with wide problems is they can be very demoralising for teams, as their wins are often small and finding and fixing edge cases can be difficult and time consuming. In addition teams will often just want these tasks to finish because they are dragging which leads to tech debt to accumulate.
Deep problems on the other hand are often easier to deal with as new functionality is often well defined, however making sure tasks don’t grow wider is key to making sure deep problems don’t become icebergs. Deep problems sometimes can be difficult if for example the feature being added requires lots of domain knowledge, or knowledge of legacy systems. In order to avoid this make sure other members of the team can do knowledge sharing about features, so other teams are not in the dark.